
Proxmox Guide FAQ / Errors / Howto
How To Enable HA in Proxmox
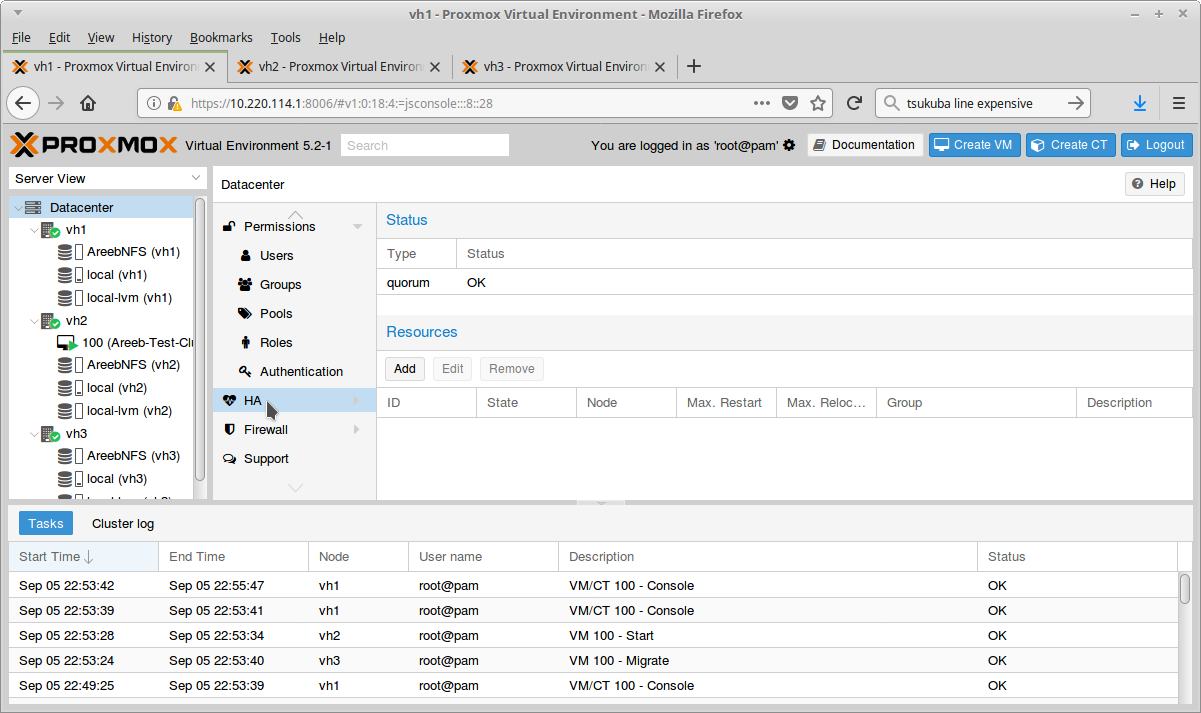
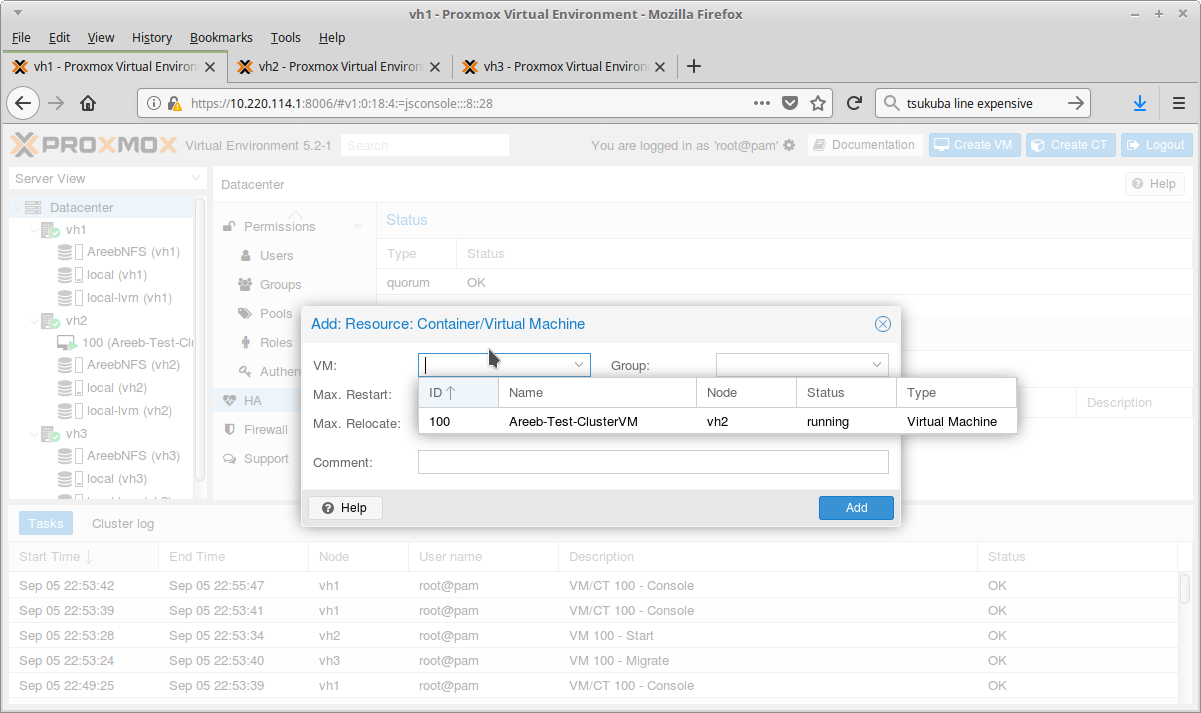
Test Your HA
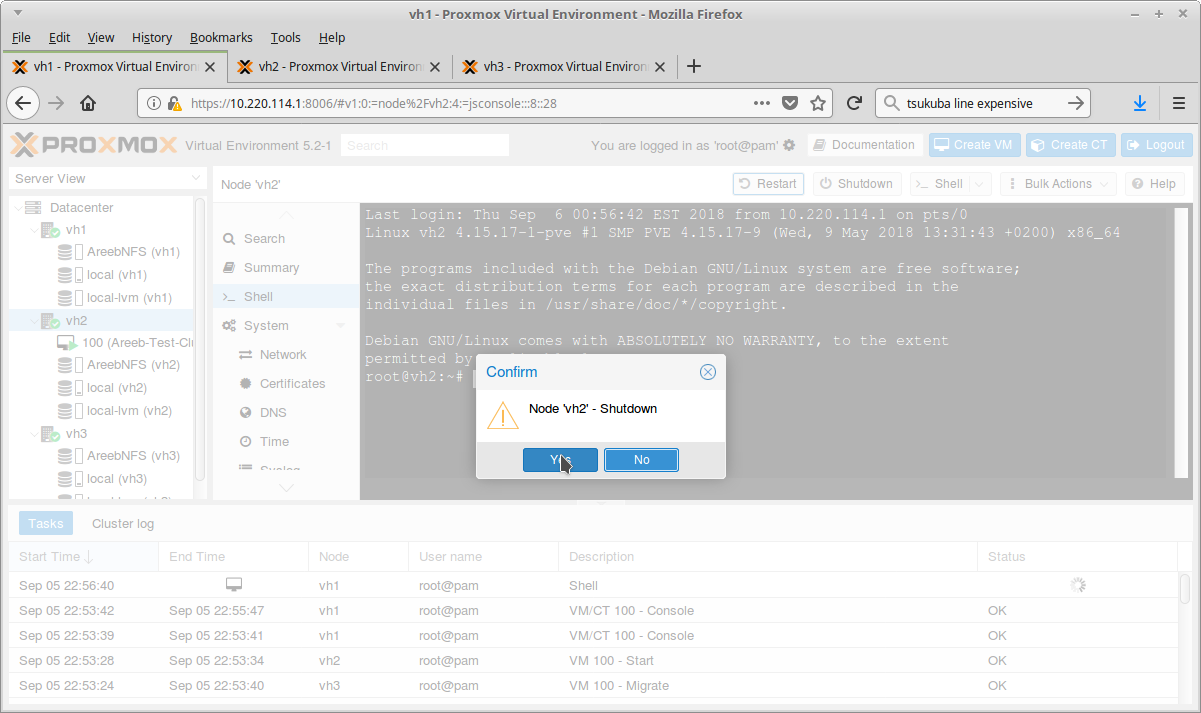
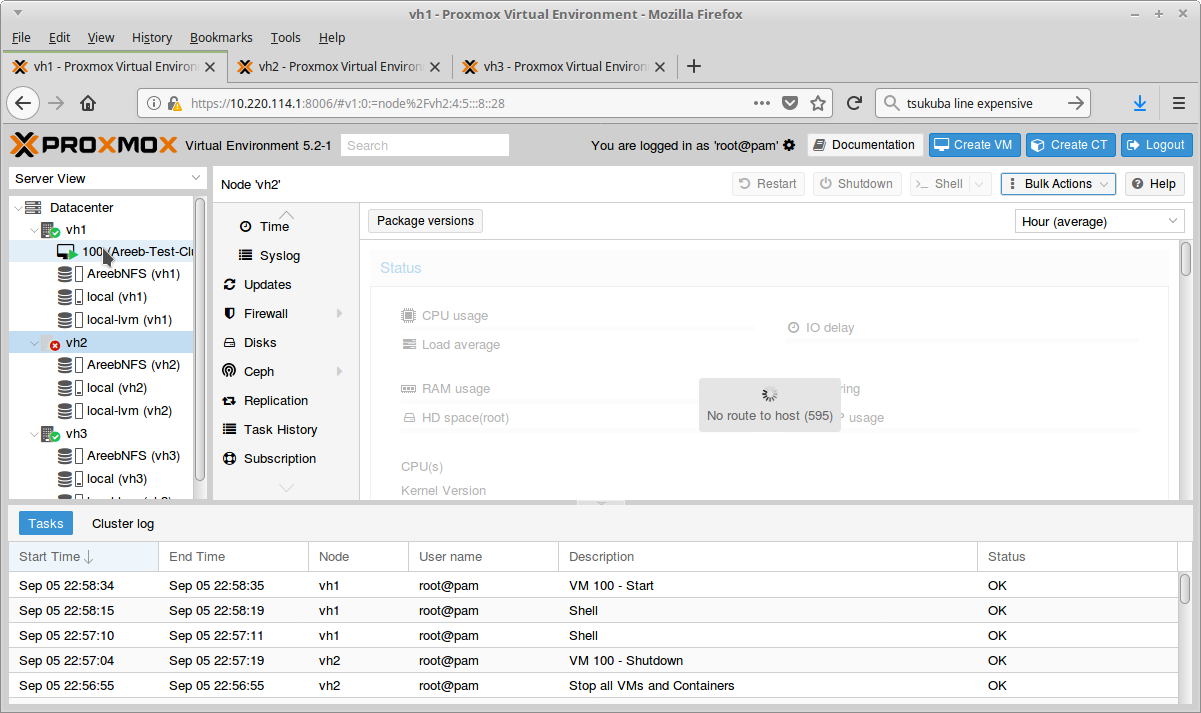
Shutdown the node that has the HA VM.
Can't Login To the GUI after changing your password?
Make sure you are using PAM authentication, but if you change your password for root, pveproxy will not accept the new password as it seems to cache the existing one. To fix this problem, restart pveproxy:
systemctl restart pveproxy
If you get a 401 ticket error and cannot see your disks, this appears to be an issue in newer version like 7.x.
If this happens when you have multiple Proxmox GUI's open, close the others (logout) and it should go away.
If it still doesn't work and continues to give the 401 ticket error check that your time is correct and the same on all nodes. If not you should make sure all nodes have ntp:
apt install ntp && systemctl start ntp
Did You Clone Your Proxmox Nodes?
You will need to follow the IP Change Guide and also the SSL Proxmox Same Certificate Error.
You should follow the correct steps to change the hostname first
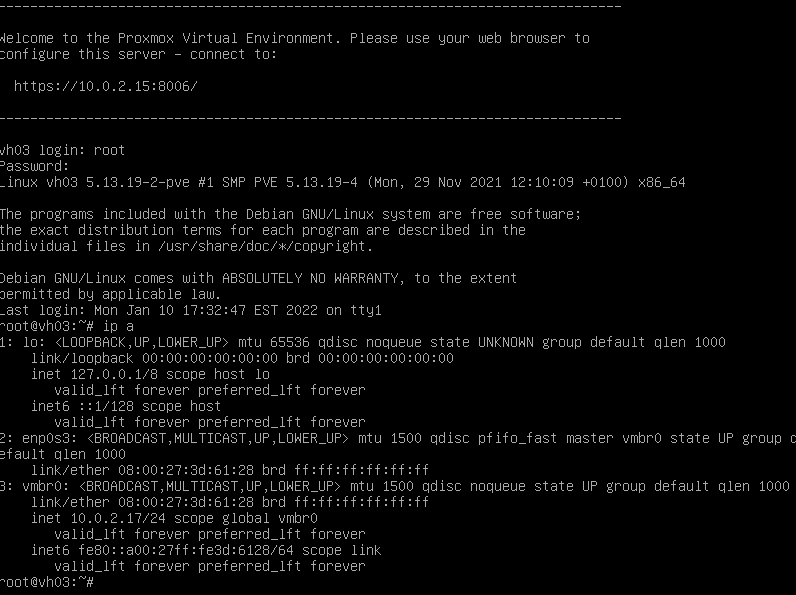
Be warned that the message "Welcome to the Proxmox Virtual Environment. Please use your web browser to configure this server - connect to: https://10.0.2.15" is static and set during install.
This means if you have DHCP or change the IP, the message will not update the correct IP. You can see yourself that this message is set in /etc/issue.
For example look at the message, but to verify you should run "ip a" to see if the IP is really the one that Proxmox says to use.
If you need to delete your cluster it is easier to start fresh this way:
If you need to delete your cluster it is easier to start fresh this way:
#stop proxmox cluster and corosync services so we can edit and remove the relevant files
systemctl stop pve-cluster
systemctl stop corosync
#mount proxmox filesystem in local mode so we can edit the files instead of being read only
pmxcfs -l
#delete all bad corosync files don't worry about the error about not being able to delete the subdir "rm: cannot remove '/etc/corosync/uidgid.d': Is a directory"
rm /etc/pve/corosync.conf
rm /etc/corosync/*
#now we can restart proxmox filesystem and the cluster service
killall pmxcfs
systemctl start pve-cluster
#if you wanted to delete a node
#pvecm cluster manager needs to be told it only needs a single vote otherwise you won't be able to delete it due to quorum requirements
pvecm expected 1
pvecm delnode nodenametodelete
Cluster Issues - Node Joined and shows under pvecm status and under "Datacenter" but not under Cluster Members.
This is often caused by ssl issues
cat /var/log/syslog|grep pve-ssl
If you get an error about SSL in the above, your certificates may be missing.
Follow the commands from here:
If the above doesn't work, it is probably best to reinstall the node (turn it off, then on the good node run pvecm delnode nodename)
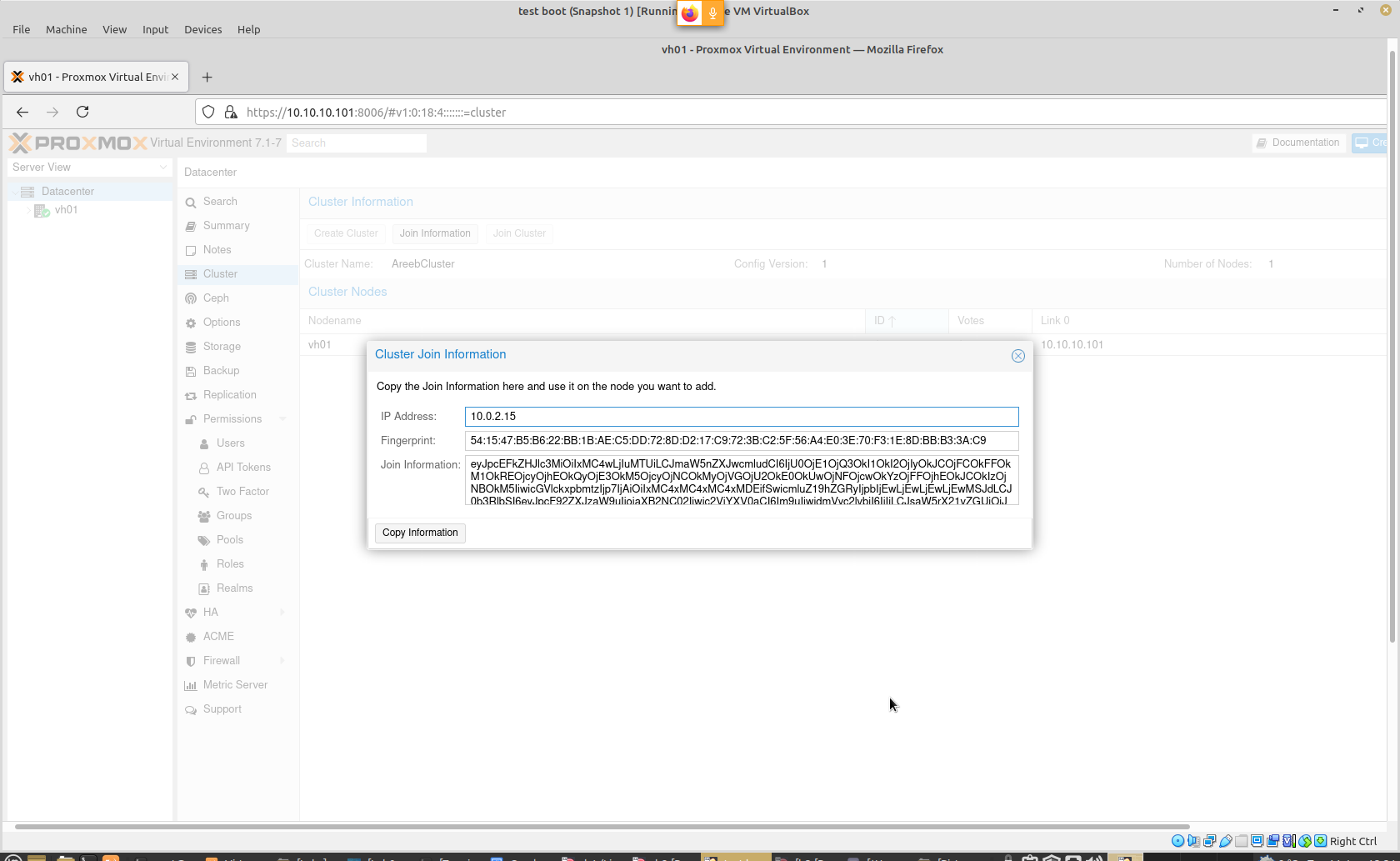
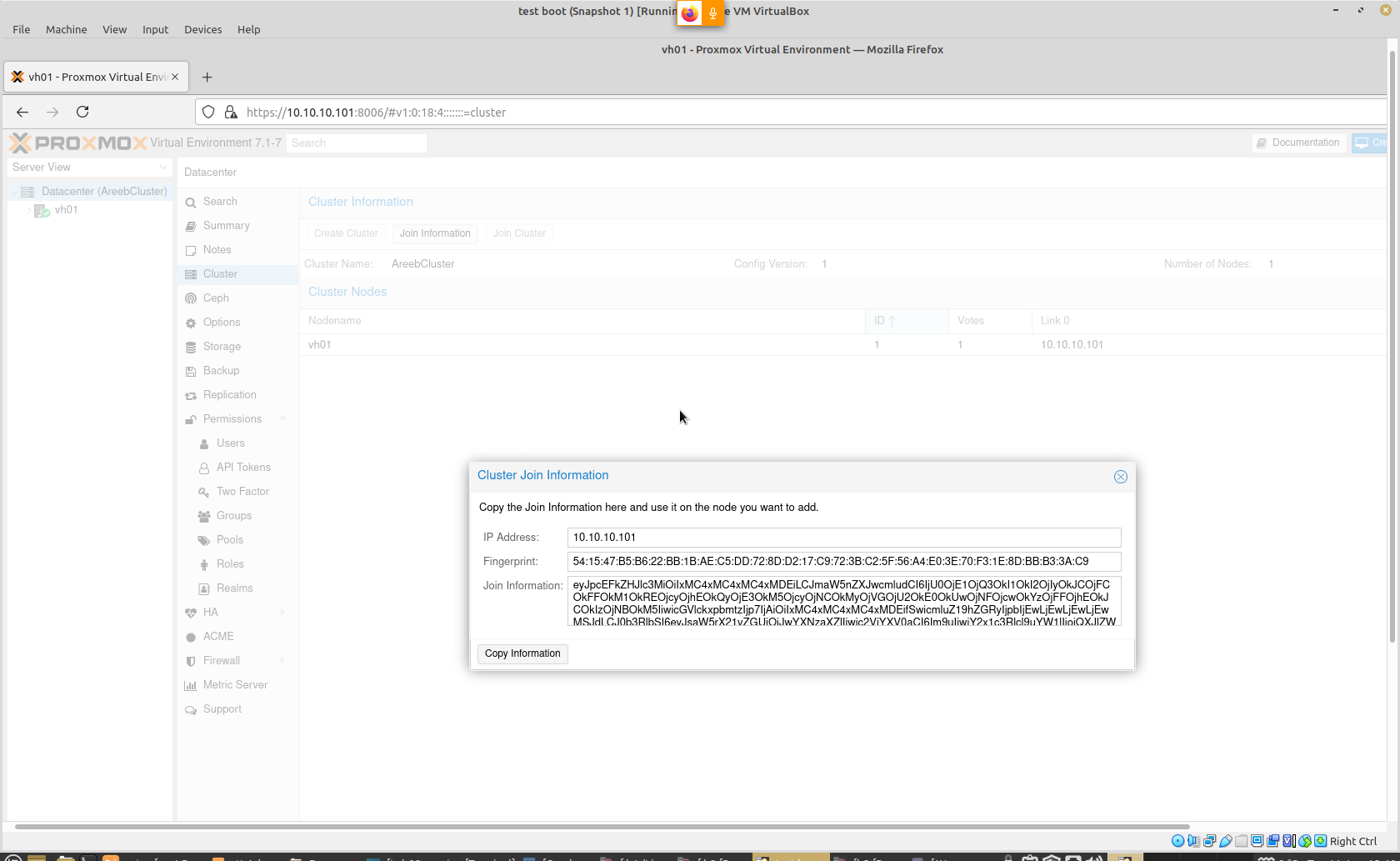
Cluster Join Address Has Wrong IP?
Note the actual IP is 10.10.10.101 but the Cluster Join IP is 10.0.2.15 which is not correct.
Solution: edit /etc/hosts and update the IP, then reboot and the correct join IP will be there.
Proxmox Same Certificate Error:
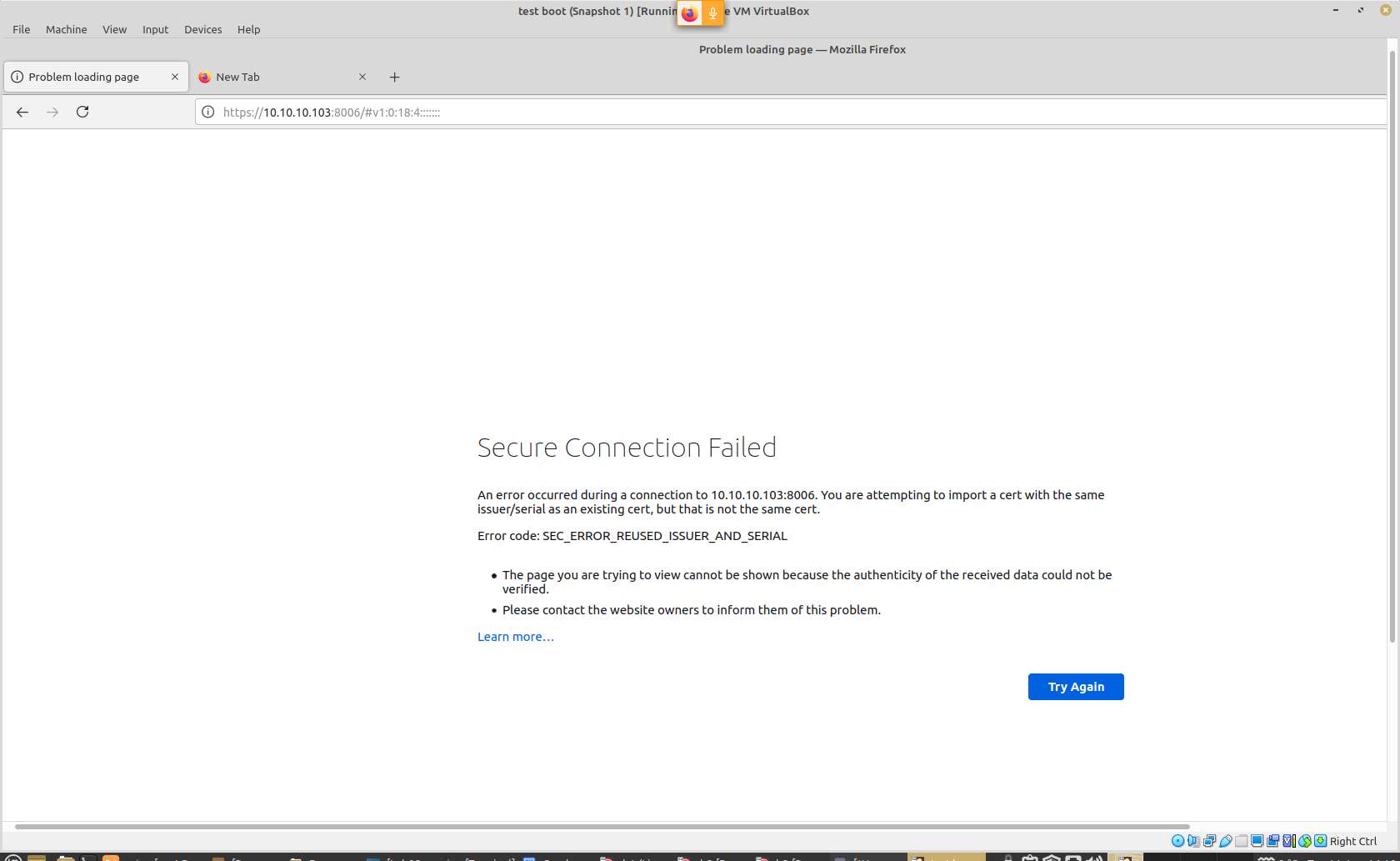
proxmox you are attempting to import a cert with the same issuer/serial as an existing cert, but is not the same cert. Error code: SEC_ERROR_REUSED_ISSUER_AND_SERIAL
rm /etc/pve/local/pve-ssl.*
rm /etc/pve/pve-root-ca.pem
pvecm updatecerts --force
systemctl restart pveproxy
When I restart a node, another goes down or reboots itself.
If you have 3 nodes and want the cluster to work with just 2, take the third node down (so only 2 are running) and then run this:
pvecm expected 2
You will get a "Unable to set expected votes: CS_ERROR_INVALID_PARAM" if you try to set the number to less than the currently running number of nodes.
Note that the number of expected votes will always by default be, how many nodes are running and it will automatically adjust itself up if you check pvecm status later on when the nodes are back online.
Ceph Issues
If you get an error 500 after install, even though it was successful the easiest way is to use this:
pveceph purge
Check all ceph services
root@vh01:~# systemctl status ceph*
● ceph-mds.target - ceph target allowing to start/stop all ceph-mds@.service instances at once
Loaded: loaded (/lib/systemd/system/ceph-mds.target; enabled; vendor preset: enabled)
Active: active since Wed 2022-01-12 16:11:41 EST; 27min ago
Jan 12 16:11:41 vh01 systemd[1]: Reached target ceph target allowing to start/stop all ceph-mds@.service instances at once.
● ceph-osd@0.service - Ceph object storage daemon osd.0
Loaded: loaded (/lib/systemd/system/ceph-osd@.service; enabled-runtime; vendor preset: enabled)
Drop-In: /usr/lib/systemd/system/ceph-osd@.service.d
└─ceph-after-pve-cluster.conf
Active: active (running) since Wed 2022-01-12 16:17:37 EST; 21min ago
Process: 7778 ExecStartPre=/usr/libexec/ceph/ceph-osd-prestart.sh --cluster ${CLUSTER} --id 0 (code=exited, status=0/SUCCESS)
Main PID: 7782 (ceph-osd)
Tasks: 59
Memory: 37.7M
CPU: 4.036s
CGroup: /system.slice/system-ceph\x2dosd.slice/ceph-osd@0.service
└─7782 /usr/bin/ceph-osd -f --cluster ceph --id 0 --setuser ceph --setgroup ceph
Jan 12 16:17:37 vh01 systemd[1]: Starting Ceph object storage daemon osd.0...
Jan 12 16:17:37 vh01 systemd[1]: Started Ceph object storage daemon osd.0.
Jan 12 16:17:39 vh01 ceph-osd[7782]: 2022-01-12T16:17:39.818-0500 7f661f1bdf00 -1 osd.0 0 log_to_monitors {default=true}
Jan 12 16:17:41 vh01 ceph-osd[7782]: 2022-01-12T16:17:41.314-0500 7f661c169700 -1 osd.0 0 waiting for initial osdmap
Jan 12 16:17:41 vh01 ceph-osd[7782]: 2022-01-12T16:17:41.338-0500 7f66176c6700 -1 osd.0 4 set_numa_affinity unable to identify public interface '' numa node: (2) No such file or directory
● ceph-crash.service - Ceph crash dump collector
Loaded: loaded (/lib/systemd/system/ceph-crash.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2022-01-12 16:11:39 EST; 27min ago
Main PID: 3785 (ceph-crash)
Tasks: 1 (limit: 4635)
Memory: 5.6M
CPU: 59ms
CGroup: /system.slice/ceph-crash.service
└─3785 /usr/bin/python3.9 /usr/bin/ceph-crash
Jan 12 16:11:39 vh01 systemd[1]: Started Ceph crash dump collector.
Jan 12 16:11:39 vh01 ceph-crash[3785]: INFO:ceph-crash:monitoring path /var/lib/ceph/crash, delay 600s
● ceph-mon.target - ceph target allowing to start/stop all ceph-mon@.service instances at once
Loaded: loaded (/lib/systemd/system/ceph-mon.target; enabled; vendor preset: enabled)
● ceph-mds.target - ceph target allowing to start/stop all ceph-mds@.service instances at once
Loaded: loaded (/lib/systemd/system/ceph-mds.target; enabled; vendor preset: enabled)
Active: active since Wed 2022-01-12 16:11:41 EST; 27min ago
Jan 12 16:11:41 vh01 systemd[1]: Reached target ceph target allowing to start/stop all ceph-mds@.service instances at once.
● ceph-osd@0.service - Ceph object storage daemon osd.0
Loaded: loaded (/lib/systemd/system/ceph-osd@.service; enabled-runtime; vendor preset: enabled)
Drop-In: /usr/lib/systemd/system/ceph-osd@.service.d
└─ceph-after-pve-cluster.conf
Active: active (running) since Wed 2022-01-12 16:17:37 EST; 21min ago
Process: 7778 ExecStartPre=/usr/libexec/ceph/ceph-osd-prestart.sh --cluster ${CLUSTER} --id 0 (code=exited, status=0/SUCCESS)
Main PID: 7782 (ceph-osd)
Tasks: 59
Memory: 37.7M
CPU: 4.036s
CGroup: /system.slice/system-ceph\x2dosd.slice/ceph-osd@0.service
└─7782 /usr/bin/ceph-osd -f --cluster ceph --id 0 --setuser ceph --setgroup ceph
Jan 12 16:17:37 vh01 systemd[1]: Starting Ceph object storage daemon osd.0...
Jan 12 16:17:37 vh01 systemd[1]: Started Ceph object storage daemon osd.0.
Jan 12 16:17:39 vh01 ceph-osd[7782]: 2022-01-12T16:17:39.818-0500 7f661f1bdf00 -1 osd.0 0 log_to_monitors {default=true}
Jan 12 16:17:41 vh01 ceph-osd[7782]: 2022-01-12T16:17:41.314-0500 7f661c169700 -1 osd.0 0 waiting for initial osdmap
Jan 12 16:17:41 vh01 ceph-osd[7782]: 2022-01-12T16:17:41.338-0500 7f66176c6700 -1 osd.0 4 set_numa_affinity unable to identify public interface '' numa node: (2) No such file or directory
● ceph-crash.service - Ceph crash dump collector
Loaded: loaded (/lib/systemd/system/ceph-crash.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2022-01-12 16:11:39 EST; 27min ago
Main PID: 3785 (ceph-crash)
Tasks: 1 (limit: 4635)
Memory: 5.6M
CPU: 59ms
CGroup: /system.slice/ceph-crash.service
└─3785 /usr/bin/python3.9 /usr/bin/ceph-crash
Jan 12 16:11:39 vh01 systemd[1]: Started Ceph crash dump collector.
Jan 12 16:11:39 vh01 ceph-crash[3785]: INFO:ceph-crash:monitoring path /var/lib/ceph/crash, delay 600s
● ceph-mon.target - ceph target allowing to start/stop all ceph-mon@.service instances at once
Loaded: loaded (/lib/systemd/system/ceph-mon.target; enabled; vendor preset: enabled)
Active: active since Wed 2022-01-12 16:11:41 EST; 27min ago
Jan 12 16:11:41 vh01 systemd[1]: Reached target ceph target allowing to start/stop all ceph-mon@.service instances at once.
● ceph.target - ceph target allowing to start/stop all ceph*@.service instances at once
Loaded: loaded (/lib/systemd/system/ceph.target; enabled; vendor preset: enabled)
Active: active since Wed 2022-01-12 16:05:27 EST; 34min ago
Warning: journal has been rotated since unit was started, output may be incomplete.
● ceph-mgr@vh01.service - Ceph cluster manager daemon
Loaded: loaded (/lib/systemd/system/ceph-mgr@.service; enabled; vendor preset: enabled)
Drop-In: /usr/lib/systemd/system/ceph-mgr@.service.d
└─ceph-after-pve-cluster.conf
Active: active (running) since Wed 2022-01-12 16:12:51 EST; 26min ago
Main PID: 5175 (ceph-mgr)
Tags: